April 01, 2019
A friend asked me this programming multiple choice question that’s been driving me nuts. Not because it was a particularly hard question, but it was just full of holes.
Given this code, what is the run-time complexity:
sum = 0
for(i = 0; i < n^2; i++)
for(j=0; j < n; j++)
for(k=0; k <j; k++)
sum++;
It didn’t take me long to figure out that the “correct” answer is that this code has the time complexity of O(n^4). Simple cs 101.
Reasoning:
The first loop takes n^2 time. Check.
The second and third loop run like this:
when j = 0, k =0, but k < j doesn’t hold. 0 runs.
when j = 1, k = 0, -> 1 run.
when j = 2, k = 0, 1, –> 2 runs.
when j = 3, k = 0, 1, 2…. -> 3 runs.
This turns out to be a summation formula: sum(1 + 2+ 3+ 4+ 5+ … n-1), which is (n-1)*(n-1+1)/2.
Combining this with the first loop, the run time is O(n^2 * (n-1)*n/2).
All in all, the time complexity is O(n^4).
But this could be wrong based under certain assumptions.
Breaking Assumption 1: Suppose that this is the second time running this code. Or the third time. If the computer running this program caches the result(s) in the computer cache, then it’s a O(c) operation. Constant time lookup. Woohoo! Done.
Breaking Assumption 2: I heard a story that clang or other compilers are super-smart. They don’t run this code, they figure out that the above code can be converted into summation formulas. So the answer is always going n^3(n+1)/2. The computer doesn’t need to run any loops! Which is probably ~a couple of load(1?) operation from the computer, and maybe 4 multiplication operations, 1 addition, and 1 division. Probably less than 20 operations total. Which is still constant amount of cpu instructions regardless of n. So it’s still constant time operations independent of the size of n.
So yes, it’s O(n^4) under certain conditions. Ugh. But considering that Big O notation is taking the asymptotic bound for the worst case situation, I guess this is the safe, right answer. But under certain conditions, there is no way the asymptotic behavior would ever be O(n^4). It really depends on your environment and other extra details.
I was super curious of what optimizations the compiler makes, and coded this up on my computer in C and generated some assembly afterwards.
#include <stdio.h>
#include <stdlib.h>
int main(int argc,char* argv[])
{
int n = atoi(argv[1]);
int i, j, k = 0;
int sum = 0;
for (i = 0; i < n*n; i++){
for (j = 0; j < n; j++){
for (k = 0; k < j; k++){
sum++;
}
}
}
printf("%d", sum);
return 0;
}
Then I converted this to assembly with clang and gcc, and started digging around:
gcc, no optimizations:
.file "dumbq.c"
.section .rodata
.LC0:
.string "%d"
.text
.globl main
.type main, @function
main:
.LFB2:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $48, %rsp
movl %edi, -36(%rbp)
movq %rsi, -48(%rbp)
movq -48(%rbp), %rax
addq $8, %rax
movq (%rax), %rax
movq %rax, %rdi
call atoi
movl %eax, -4(%rbp)
movl $0, -12(%rbp)
movl $0, -8(%rbp)
movl $0, -20(%rbp)
jmp .L2
.L7:
movl $0, -16(%rbp)
jmp .L3
.L6:
movl $0, -12(%rbp)
jmp .L4
.L5:
addl $1, -8(%rbp)
addl $1, -12(%rbp)
.L4:
movl -12(%rbp), %eax
cmpl -16(%rbp), %eax
jl .L5
addl $1, -16(%rbp)
.L3:
movl -16(%rbp), %eax
cmpl -4(%rbp), %eax
jl .L6
addl $1, -20(%rbp)
.L2:
movl -4(%rbp), %eax
imull -4(%rbp), %eax
cmpl -20(%rbp), %eax
jg .L7
movl -8(%rbp), %eax
movl %eax, %esi
movl $.LC0, %edi
movl $0, %eax
call printf
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE2:
.size main, .-main
.ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.11) 5.4.0 20160609"
.section .note.GNU-stack,"",@progbits
clang, no optimizations:
.text
.intel_syntax noprefix
.file "dumbq.c"
.globl main
.align 16, 0x90
.type main,@function
main: # @main
.cfi_startproc
# BB#0:
push rbp
.Ltmp0:
.cfi_def_cfa_offset 16
.Ltmp1:
.cfi_offset rbp, -16
mov rbp, rsp
.Ltmp2:
.cfi_def_cfa_register rbp
sub rsp, 48
mov dword ptr [rbp - 4], 0
mov dword ptr [rbp - 8], edi
mov qword ptr [rbp - 16], rsi
mov rsi, qword ptr [rbp - 16]
mov rdi, qword ptr [rsi + 8]
call atoi
mov dword ptr [rbp - 20], eax
mov dword ptr [rbp - 32], 0
mov dword ptr [rbp - 36], 0
mov dword ptr [rbp - 24], 0
.LBB0_1: # =>This Loop Header: Depth=1
# Child Loop BB0_3 Depth 2
# Child Loop BB0_5 Depth 3
mov eax, dword ptr [rbp - 24]
mov ecx, dword ptr [rbp - 20]
imul ecx, dword ptr [rbp - 20]
cmp eax, ecx
jge .LBB0_12
# BB#2: # in Loop: Header=BB0_1 Depth=1
mov dword ptr [rbp - 28], 0
.LBB0_3: # Parent Loop BB0_1 Depth=1
# => This Loop Header: Depth=2
# Child Loop BB0_5 Depth 3
mov eax, dword ptr [rbp - 28]
cmp eax, dword ptr [rbp - 20]
jge .LBB0_10
# BB#4: # in Loop: Header=BB0_3 Depth=2
mov dword ptr [rbp - 32], 0
.LBB0_5: # Parent Loop BB0_1 Depth=1
# Parent Loop BB0_3 Depth=2
# => This Inner Loop Header: Depth=3
mov eax, dword ptr [rbp - 32]
cmp eax, dword ptr [rbp - 28]
jge .LBB0_8
# BB#6: # in Loop: Header=BB0_5 Depth=3
mov eax, dword ptr [rbp - 36]
add eax, 1
mov dword ptr [rbp - 36], eax
# BB#7: # in Loop: Header=BB0_5 Depth=3
mov eax, dword ptr [rbp - 32]
add eax, 1
mov dword ptr [rbp - 32], eax
jmp .LBB0_5
.LBB0_8: # in Loop: Header=BB0_3 Depth=2
jmp .LBB0_9
.LBB0_9: # in Loop: Header=BB0_3 Depth=2
mov eax, dword ptr [rbp - 28]
add eax, 1
mov dword ptr [rbp - 28], eax
jmp .LBB0_3
.LBB0_10: # in Loop: Header=BB0_1 Depth=1
jmp .LBB0_11
.LBB0_11: # in Loop: Header=BB0_1 Depth=1
mov eax, dword ptr [rbp - 24]
add eax, 1
mov dword ptr [rbp - 24], eax
jmp .LBB0_1
.LBB0_12:
movabs rdi, .L.str
mov esi, dword ptr [rbp - 36]
mov al, 0
call printf
xor esi, esi
mov dword ptr [rbp - 40], eax # 4-byte Spill
mov eax, esi
add rsp, 48
pop rbp
ret
.Lfunc_end0:
.size main, .Lfunc_end0-main
.cfi_endproc
.type .L.str,@object # @.str
.section .rodata.str1.1,"aMS",@progbits,1
.L.str:
.asciz "%d"
.size .L.str, 3
.ident "clang version 3.8.0-2ubuntu4 (tags/RELEASE_380/final)"
.section ".note.GNU-stack","",@progbits
gcc O3 optimization:
.file "dumbq.c"
.section .rodata.str1.1,"aMS",@progbits,1
.LC0:
.string "%d"
.section .text.unlikely,"ax",@progbits
.LCOLDB1:
.section .text.startup,"ax",@progbits
.LHOTB1:
.p2align 4,,15
.globl main
.type main, @function
main:
.LFB38:
.cfi_startproc
subq $8, %rsp
.cfi_def_cfa_offset 16
movq 8(%rsi), %rdi
movl $10, %edx
xorl %esi, %esi
call strtol
movl %eax, %edi
xorl %edx, %edx
xorl %r8d, %r8d
imull %eax, %eax
testl %eax, %eax
je .L3
.p2align 4,,10
.p2align 3
.L10:
xorl %esi, %esi
testl %edi, %edi
jle .L4
leal 1(%rsi), %ecx
cmpl %edi, %ecx
je .L4
.p2align 4,,10
.p2align 3
.L16:
testl %ecx, %ecx
jle .L6
leal 1(%rdx,%rsi), %edx
.L6:
movl %ecx, %esi
leal 1(%rsi), %ecx
cmpl %edi, %ecx
jne .L16
.L4:
addl $1, %r8d
cmpl %r8d, %eax
jne .L10
.L3:
movl $.LC0, %esi
movl $1, %edi
xorl %eax, %eax
call __printf_chk
xorl %eax, %eax
addq $8, %rsp
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE38:
.size main, .-main
.section .text.unlikely
.LCOLDE1:
.section .text.startup
.LHOTE1:
.ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.11) 5.4.0 20160609"
.section .note.GNU-stack,"",@progbits
clang O3 optimization:
.text
.intel_syntax noprefix
.file "dumbq.c"
.globl main
.align 16, 0x90
.type main,@function
main: # @main
.cfi_startproc
# BB#0:
push rbx
.Ltmp0:
.cfi_def_cfa_offset 16
.Ltmp1:
.cfi_offset rbx, -16
mov rdi, qword ptr [rsi + 8]
xor ebx, ebx
xor esi, esi
mov edx, 10
call strtol
mov ecx, eax
imul ecx, ecx
test ecx, ecx
je .LBB0_3
# BB#1:
test eax, eax
jle .LBB0_3
# BB#2: # %.preheader.lr.ph.us.preheader
lea edx, [rax - 1]
lea esi, [rax - 2]
imul rsi, rdx
shr rsi
lea edx, [rax + rsi - 1]
test ecx, ecx
mov edi, 1
cmovg edi, ecx
dec edi
imul edi, edx
add edi, eax
lea ebx, [rsi + rdi - 1]
.LBB0_3: # %._crit_edge10
mov edi, .L.str
xor eax, eax
mov esi, ebx
call printf
xor eax, eax
pop rbx
ret
.Lfunc_end0:
.size main, .Lfunc_end0-main
.cfi_endproc
.type .L.str,@object # @.str
.section .rodata.str1.1,"aMS",@progbits,1
.L.str:
.asciz "%d"
.size .L.str, 3
.ident "clang version 3.8.0-2ubuntu4 (tags/RELEASE_380/final)"
.section ".note.GNU-stack","",@progbits
Results:
Without optimizations, the assembly code follows the logic and loops. With optimizations, it’s skipping all this with xor computations, and reduces the number of instructions. But it still doesn’t seem to use the obvious summation formulas(not quite sure…)… =(. OK - It’s not a couple of cpu operations. Unfortunately, I’m super rusty in my assembly, so I’ll have to explore this a a bit more another time. But I can almost swear that this code can be written in assembly in a couple of instructions and should not be dependent on n…
March 30, 2019
My Recurse Center batch(Winter 2 2019 is the best!) officially ended Friday. It’s one of the best experiences I had in my life. I will surely miss it.
I’m going back to my hometown in the suburbs of D.C., take some time to read and relax, and hopefully travel for a bit after while I’m planning my next steps. The most likely outcome is to come back to New York to work.
Reasons to Come to the Recurse Center:
- You will learn things you didn’t know you didn’t know.
- There’s a diverse range of programmers with different skillsets. It strikes a nice balance, because you get an opportunity to help and share your knowledge. At the same time, there are always people to learn programming from. Because everyone has different backgrounds, you get to pick up on other interesting things.
- People at Recurse are super nice and friendly. Recurse has an interview process where they optimize for picking people based on their passion and whether they’re someone Recursers would get along with(That’s my theory anyway). I didn’t interact with everyone in my batch, maybe because we never got a chance to talk or wasn’t on the same wavelength. But I found no one that was outright rude or mean. Yet.
- You get access to a community of 1500 people on Recurse Center’s private messaging board. That’s one more community you can ask programming questions or other life questions.
- Collaboration. You do get a chance to collaborate on projects together and pair up, if you choose to do so.
- Sometimes, while you’re working on your projects alone, it can get lonely, or possibly stuck. What I found inspirational was that there was always someone passionately hacking away and learning when I felt drained, and that I could talk to others to take a quick break.
- Recurse is free.
Reasons Against:
- Money doesn’t grow on trees. Let’s say that you need 7k to fund yourself for Recurse. It’s not only 7k, but you also have to factor in the opportunity cost of what you could have been doing when you’re not at Recurse. Which is a lot of monies.
- You want to focus only on working on your project at maximal velocity. Then it may be better to stay home. There will be distractions(some good, like getting to know some really cool things you didn’t know, but others not as good). James, an alumni, said this: If your sole reason is to come to Recurse to work on your project flying solo, Recurse may not be the best option for you. I mean, you can work on your passion project by yourself right? So expect your original goals to shift.
- You are an early stage programmer and want to get a job through Recurse’s partner companies. Many of their partner companies mostly want senior software engineers.
- Sometimes, you feel that you’re not good enough because other people are doing amazing things and you’re either not making a lot of progress, or learning something that doesn’t have tangible results. But the other side of the coin is that the work of others rekindles your fire to learn.
- New York is hectic and noisy. Well that’s not a Recurse thing, but I couldn’t think of any other con ¯\(ツ__/¯
Recommended Optimal Recurse Strategy:
Get a job that you really love, and take a sabbatical. One of the Recurse facilitators mentioned this before I started my batch. People have a hard time juggling between planning their next steps, and enjoying the Recurse experience. I would have loved my batch much more if I took a sabbatical, didn’t have to worry about interview prep, and went ham!
Some Recursers got their companies to fund their learning experience. This is sick. If you love your job, but want a break, you should definitely ask! You’re going to end up becoming a better programmer, so the company should invest in your 3 month ordeal!
Also, it’s better if you’re not strapped for cash. It’s stressful to worry about money when you don’t have any. It’s good to save up some money so you can go out often and explore New York!
Advice to Future Recursers:
- Introduce yourself to other Recursers as soon as possible. The sooner you do this, the less awkward the two of you will be. Sometimes, you never really introduce yourself to each other, so naturally you tend to avoid talking to each other because it’s gotten awkward. It’s a crappy feedback loop, so don’t do it.
- Organize study groups and find people to learn together. I recommend this because it’s a lot more fun this way, and you get to clarify missing pieces in whatever you are studying. Or go in-depth through another side discussion.
- Don’t be afraid to ask to join in on the conversation. But don’t be afraid to bounce as well.
- Ask away. Personally I don’t think there is a dumb question. I saw this blog post recently which is relevant(https://thesquareplanet.com/blog/why-dont-people-ask-questions/). It’s pretty safe here.
- Give presentations. You get a chance to do 5 minute presentations every week. In retrospect, this is what I should have done more(I gave 2 during my stay). If you’re bad at public speaking, this is an excellent, low-risk way to improve.
- Pair program often. There are some interesting tools and ideas that I’ve picked up during the few sessions I’ve had with others.
Overall, I highly recommend attending the Recurse Center for anyone interested.
*Nothing is permanent in life, so this blog post is subject to revision =D.
My Recurse Center batch(Winter 2 2019 is the best!) officially ended Friday. It’s one of the best experiences I had in my life. I will surely miss it.
I’m going back to my hometown in the suburbs of D.C., take some time to read and relax, and hopefully travel for after while I’m planning my next steps.
Reasons to Come to the Recurse Center:
- You will learn things you didn’t know you didn’t know.
- There’s a diverse range of programmers with different skillsets. It strikes a nice balance, because you get an opportunity to help and share your knowledge. At the same time, there are always people to learn programming from. Because everyone has different backgrounds, you get to pick up on other interesting things.
- People at Recurse are super nice and friendly. Recurse has an interview process where they optimize for picking people based on their passion and whether they’re someone Recursers would get along with(That’s my theory anyway). F I didn’t interact with everyone in my batch, maybe because we never got a chance to talk or wasn’t on the same wavelength. But I found no one that was outright rude or mean. Yet.
- You get access to a community of 1500 people on Recurse Center’s private messaging board. That’s one more community you can ask programming questions or other life questions.
- Collaboration. You do get a chance to collaborate on projects together and pair up, if you choose to do so.
- Sometimes, while you’re working on your projects alone, it can get lonely, or possibly stuck. What I found inspirational was that there was always someone passionately hacking away and learning when I felt drained, and that I could talk to others to take a quick break.
- Recurse is free.
Reasons Against:
- Money doesn’t grow on trees. Let’s say that you need 7k to fund yourself for Recurse. It’s not only 7k, but you also have to factor in the opportunity cost of what you could have been doing when you’re not at Recurse. Which is a lot of monies.
- You want to focus only on working on your project at maximal velocity. Then it may be better to stay home. There will be distractions(some good, like getting to know some really cool things you didn’t know, but others not as good). James, an alumni, said this: If your sole reason is to come to Recurse to work on your project flying solo, Recurse may not be the best option for you. I mean, you can work on your passion project by yourself right? So expect your original goals to shift.
- Your an early stage programmer and want to get a job through Recurse’s partner companies. Many of their partner companies mostly want senior software engineers.
- Sometimes, you feel that you’re not good enough because other people are doing amazing things and you’re either not making a lot of progress, or learning something that doesn’t have tangible results. But the other side of the coin is that the work of others rekindles your fire to learn.
- New York is hectic and noisy. Well that’s not a Recurse thing, but I couldn’t think of any other con ¯\(ツ__/¯
Recommended Optimal Recurse Strategy:
Get a job that you really love, and take a sabbatical. One of the Recurse facilitators mentioned this before I started my batch. People have a hard time juggling between planning their next steps, and enjoying the Recurse experience. I would have loved my batch much more if I took a sabbatical, didn’t have to worry about interview prep, and went ham!
Some Recursers got their companies to fund their learning experience. This is sick. If you love your job, but want a break, you should definitely ask! You’re going to end up becoming a better programmer, so the company should invest in your 3 month ordeal!
Also, it’s better if you’re not strapped for cash. It’s stressful to worry about money when you don’t have any. It’s good to save up some money so you can go out often and explore New York!
Overall, I highly recommend attending the Recurse Center for anyone interested. It’s changed my perspective on life, and reinvigorated me to continue learning just for the sake of it.
*Nothing is permanent in life, so this blog post is subject to revision =D.
March 28, 2019
One of the most fascinating things I’ve realized is that for every argument, the same set of facts or assumptions can be used for a counterargument. By examining the argument and going down deep enough or generalizing the meaning of the words through their ambiguity, there’s a high possibility that you can extract out a counter argument.
Here are a couple of examples:
Warning: I may not agree with everything stated below.
Life is short. So you should make the best of it.
Life is short. So short that whatever you do doesn’t matter. At all.
All life is precious. So we should not support abortion.
All life is precious.We should not force babies to be born in a world where their parents didn’t want them, if life is precious.
It’s a once in a lifetime opportunity. You need to come to this event.
it’s a once in a lifetime opportunity. Staying at home is a once in a lifetime opportunity(technically the truth).
Below is a somewhat relevant quote:
“The opposite of a correct statement is a false statement. But the opposite of a profound truth may well be another profound truth.”
― Niels Bohr
March 18, 2019
Always have backups. Whether that be things in real life or in the cyberspace.
So the ultimate irony is that while I was writing this post I my original writing went away. So.. I’m putting my drafts on Google docs now =/. BUT - the advice is always back up your things, there are things that you must do for backups to be effective. First, make sure you check that the backups are working, and subsequently do simple maintenance on backups.
In cyberspace, I use backup services like DropBox, or use version control like git. But what you have to realize that you can have backups in real life too!
Back in college, one of my good buddies Chris gave me an amazing piece of advice. He was a non-traditional college student who had a stint at the Army, so he definitely knew a few life hacks. He told me that there could be cases where he would get excessively drunk. Of course, bad things can happen if one is ever that drunk…. There’s a possibility that it would be 5 am and he could have lost all his stuff an hour ago. So he always carried a 20 dollar bill beneath the sole of his shoe.
This is really smart. So this is what I started doing, and I do have some sense of safety with the backup. Often times back in college, if I didn’t bring my wallet, I’d use that bill to go grab a drink. Nowadays, I also carry around a 20 dollar bill on the back of my phone too - it’s useful, mainly on the principle that you forget about it. It’s nice to know that if you get robbed or just forget all your stuff, you still have some cash to fall back on. Or to buy metro card in New York City =D.
In general, if you can afford it, it’s nice to have duplicate copies of all your necessities. It could be a hassle or be costly now, but it will save dividends on that off chance that your first item goes missing, or if you cannot acquire it anymore. An instance of this is when manufacturers discontinue your favorite products. This unfortunately happened with my favorite mouse - G303 Apex. Logitech stopped making it, and the price of the mouse went from $30 to around $200. I still regret not buying extra ones… If money isn’t a concern, it’s good to stock up on your favorite items goods.
Other things I back up in life:
Computer charger? I keep one in my backpack but also one in my workplace and office. I also carry around a portable battery pack inside my jacket, because one time I got stranded in the middle of Manhattan with a dead phone. Nope, not doing that again.
Earphones? I have a backup earphone in my main carry gym bag as well as my backpack. Also one in my keychain pouch.
Glasses? I’m effectively blind if I don’t have them. There’s a spare pair in my backpack as well as my car.
Recently, I’ve been going to the gym, and what always irks me is that I always forget something. I forget my workout shirt one day. I’ve also forgotten my underwear as well. Then the deodorant. Then the towel. All of these are non-critical. There are workarounds… but the workarounds are not fun either.
At a certain point, I thought… damn this is stupid. Enough is enough. I allocated a separate compartment in my bag so I have a spare set of everything. Now I carry two pairs of underwear, two pairs of socks, two bars of soap, etc. So far the problems have went away, and I think it’ll be fine as long as I do some maintenance on my gym bag.
But with respect to the backups, what’s fascinating is that if you’re relying on having at least one object to be functional, it only takes a one critical path for failure. All other paths will turn out to be a good outcome. This can be modeled as a tree!
Consider this toy problem: we want at least one computer to be functional at one time. It would look something like this if we had three computers:
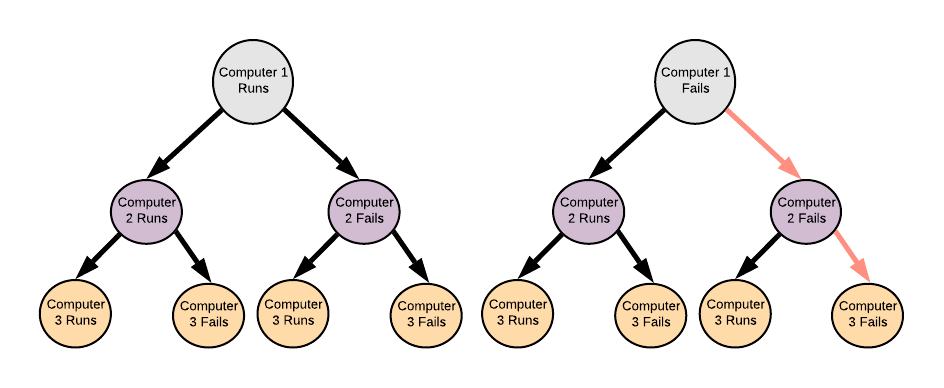
For catastrophic failure where nothing is available, there’s only one branch that you have to take that will cause a catastrophic failure. For each computer/(or any kind of object), you are adding another layer of the 2^n tree. Thus, your probability of failure would be 1 - p^n, where p is the probability of failure of that one thing(Of course, we’re making a lot of assumptions here).
Furthermore, if we assume p = 0.05. The graph of it would look like this:
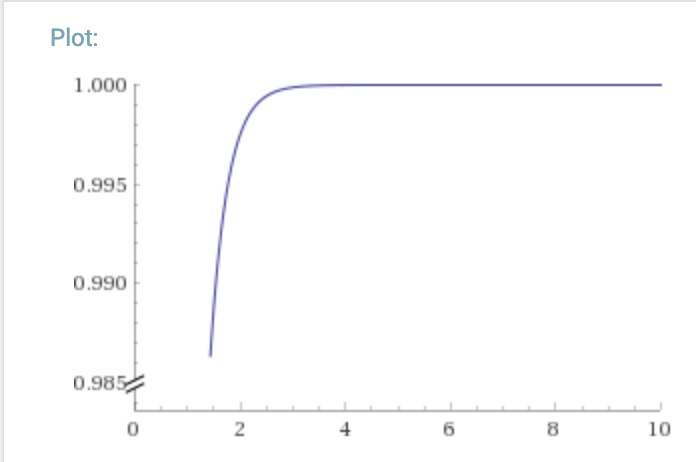
This, depending on your use case, you should decide on how many copies or n backups to have. The failure rate will determine the reliability. In general, What’s fascinating is the drop from adding one additional backup - 0.95 vs. 0.9975.But at a certain point backups aren’t worth it. It’s up to you the designer to choose that cutoff point. For me and my life, usually 2 backups seem to be a good rule of thumb.
March 03, 2019
I had my onsite interviews for two companies that I’d like to work for this past week in Seattle. I don’t think I got those jobs, because there’s so many things that I could have done better. But given what I knew then, I’m not sure if I can do significantly better. But if I knew what I know now, I would:
- Focus on writing code a lot faster. I think one of the problems is I take too much time writing code.
- When someone is watching you and you’re being graded while you’re on a whiteboard, you tend to choke. So my advice to myself next time is.. do as many mock interviews as possible. Sure, you need to do a ton of problems to be able to identify what the problems types are, but there’s no point in doing this if you are not comfortable explaining your thought process to the interviewer. There’s a chance that you will completely bomb the interview because you didn’t practice explaining your thoughts and communicating effectively.
- Expand and detail all the answers. Be as explicit as possible. It’s better to throw out all the things on your mind, even if it’s wrong, rather than leave the interviewer in the dark. They might also help you if you throw out a good idea, even if you think it is bad. It might actually be good.
- Focus on really understanding the principles behind solving each problem. Personally, I think it’s important that you understand a few set of problems very well to explain the reasoning and approaches, rather than shotgun the total number of problems. Simply put, if you can’t explain how to solve the problem and your approach, i.e. explain why the asymptotic run time is the way it is, then you’ve memorized the problem. You never understood it. What I find that is helpful is that when I’m seeing other people’s implementations, it’s so much helpful to always go through the solution code on a concrete example. If I could do the interview prep all over, I’d summarize the big principle takeaways for all the problems I do and drill it down. Maybe even make a YouTube video for them.
- Screw the job part. Go in there to learn and have fun. I think this mindset is powerful and effective.
- When the interviewer give you a hint, or tries to lead you to the right direction. Drop the approach you’ve taken and seriously consider what he’s trying to tell you. Seriously. Stop. DO NOT GET STUCK IN A LOCAL MINIMUM. And look deeply and wide about what you’re doing. Ugh. I think this is the most important part I need to work on. But it’s so hard to get out of tunnel vision mode.
Anyhoo, I did definitely learn a lot, and for my next set of jobs I am looking forward to improving my skills with these newfound lessons.